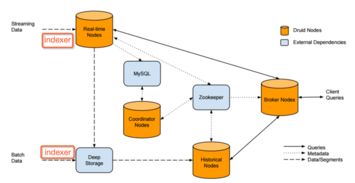
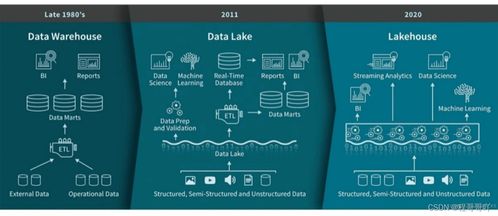
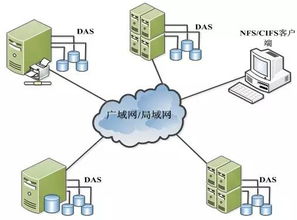
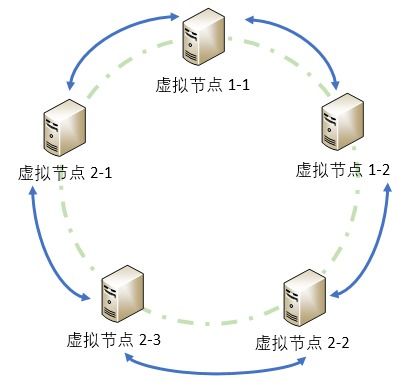
分布式数据缓存技术 数据处理与存储支持服务的核心引擎
在当今数据驱动的时代,海量、高并发的数据访问需求对传统数据处理与存储架构提出了严峻挑战。分布式数据缓存技术应运而生,它通过在应用程序与底层数据存储(如数据库)之间构建一层高速缓存,有效缓解了数据访问瓶颈,成为现代数据处理和存储支持服务的核心引擎。
一、 分布式数据缓存技术概述
分布式数据缓存是一种将数据分散存储在多台服务器内存中的技术。其核心思想是将频繁访问的“热数据”保留在访问速度极快的内存中,从而避免每次请求都去访问相对较慢的磁盘数据库(如关系型数据库)。与单机缓存相比,分布式缓存通过集群化部署,不仅提供了远超单机内存的容量,还通过数据分片(Sharding)和复制(Replication)机制,实现了高可用性、高扩展性和负载均衡。
二、 核心技术原理与主流方案
- 数据分片与一致性哈希:为了将海量数据分布到多个缓存节点,并保证节点的动态增删(扩缩容)对系统影响最小,一致性哈希算法被广泛采用。它能确保在节点变动时,仅有少量数据需要迁移,最大限度地保持缓存命中率。
- 高可用与数据持久化:通过主从复制、哨兵(Sentinel)模式或集群模式,实现故障自动转移,保证服务不间断。部分缓存系统(如Redis)支持将内存数据异步持久化到磁盘,防止系统重启导致数据完全丢失。
- 内存数据结构与高性能:利用内存直接操作,并提供丰富的数据结构(如字符串、哈希、列表、集合、有序集合等),使复杂的数据操作能在缓存层直接完成,极大提升效率。
- 主流技术方案:
- Redis:最流行的开源内存数据结构存储,支持持久化、主从复制、哨兵和集群模式,功能丰富,性能卓越。
- Memcached:经典的分布式内存对象缓存系统,设计简单,专注于键值缓存,在多核环境下性能表现优异。
- Ehcache:成熟的Java进程内缓存框架,也支持分布式部署,与Java应用生态集成度高。
三、 对数据处理与存储支持服务的关键价值
分布式缓存作为数据处理管道中的关键组件,为上层服务提供了至关重要的支持:
- 性能加速器:这是其最核心的价值。将数据库的查询结果、复杂计算结果、会话状态等存储在缓存中,后续请求可直接读取,响应时间从毫秒级降至微秒甚至纳秒级,极大提升了应用程序的吞吐量和用户体验。
- 数据库压力保护伞:有效拦截大部分高频读请求,甚至部分写请求(如先写缓存,再异步落库),避免了数据库在流量峰值时过载,提高了整个系统架构的稳定性和伸缩能力。
- 支持复杂数据处理场景:
- 热点数据访问:应对电商秒杀、社交热点等场景下的极端并发读取。
- 分布式会话存储:在微服务或无状态架构中,集中管理用户会话信息。
- 排行榜与计数器:利用Redis的有序集合等结构,轻松实现实时排行榜、点击量统计等功能。
- 消息队列与发布订阅:作为轻量级消息中间件,支持服务间的异步通信和解耦。
- 提升系统扩展性:通过简单地增加缓存节点,即可线性提升系统的整体缓存容量和处理能力,适应业务增长。
四、 实践挑战与最佳实践
引入分布式缓存也带来了新的复杂性,需要在实践中妥善处理:
- 缓存一致性:如何保证缓存数据与底层数据库数据的一致性是一个经典难题。常用策略包括设置合理的过期时间(TTL)、采用“先更新数据库,再删除缓存”的延迟双删策略、或利用数据库binlog监听(如Canal)进行异步更新。
- 缓存穿透:大量请求查询一个根本不存在的数据,导致请求直接压到数据库。解决方案:对不存在的数据也进行短暂缓存(空值缓存)、使用布隆过滤器预先校验。
- 缓存击穿:某个热点key过期瞬间,大量并发请求直接击穿缓存访问数据库。解决方案:设置热点key永不过期,或使用互斥锁(如Redis的SETNX)保证仅一个线程回源数据库。
- 缓存雪崩:大量缓存key在同一时间大规模失效,导致所有请求涌向数据库。解决方案:分散缓存过期时间(添加随机值)、保证缓存服务的高可用性、实施服务熔断降级机制。
五、 未来展望
随着云计算、微服务和实时计算的发展,分布式缓存技术的角色愈发重要。未来趋势可能包括:与持久化存储更紧密的融合(如Redis Module)、更好地支持多模型数据、在Serverless架构中作为高效的状态存储层,以及通过硬件加速(如持久内存PMem)进一步突破性能与成本的边界。
总而言之,分布式数据缓存已从一项可选的性能优化技术,演进为构建高并发、低延迟、高可用现代数据处理和存储服务不可或缺的基石。合理设计与运用缓存,是释放数据价值、驱动业务创新的关键技术手段。
如若转载,请注明出处:http://www.opulencespring.com/product/40.html
更新时间:2026-04-16 12:19:30