Hive数据仓库 数据处理与存储支持的强大服务
概述
Hive是基于Hadoop构建的数据仓库工具,旨在提供高效的数据处理与存储支持服务。它将结构化的数据文件映射为数据库表,并通过类SQL语言(HiveQL)进行查询和分析,极大地降低了大数据处理的门槛,特别适用于数据仓库、批量处理和即席查询等场景。
数据处理支持
1. 数据查询与分析
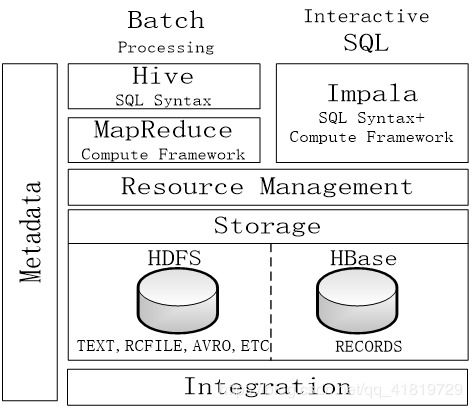
HiveQL支持丰富的查询操作,包括SELECT、JOIN、GROUP BY等,并内置大量聚合函数(如SUM、AVG、COUNT)和窗口函数,便于复杂分析。通过将查询转换为MapReduce、Tez或Spark任务,Hive可高效处理PB级数据,尤其适合批处理作业。
2. 数据转换与清洗
Hive提供灵活的数据转换功能。例如,可通过INSERT OVERWRITE或INSERT INTO语句将查询结果写入新表,实现数据清洗和聚合。支持自定义函数(UDF)和转换脚本,满足个性化处理需求,如日期格式化或文本解析。
3. 分区与分桶优化
为提升查询性能,Hive支持分区和分桶机制:
- 分区:根据日期、地区等列将数据分割存储,查询时可跳过无关分区,减少扫描数据量。
- 分桶:将数据哈希散列到固定数量的桶中,优化JOIN和采样操作,提升并行处理效率。
4. 复杂数据类型支持
除了基本类型,Hive还支持数组(ARRAY)、映射(MAP)和结构体(STRUCT)等复杂数据类型,便于处理嵌套或半结构化数据(如JSON日志),增强了数据建模的灵活性。
存储支持服务
1. 多样化存储格式
Hive支持多种存储格式,以适应不同场景:
- 文本格式(如CSV、JSON):易于阅读和交换,但压缩和查询效率较低。
- 列式存储格式(如ORC、Parquet):提供高压缩比和列裁剪能力,显著提升查询性能,适合分析型负载。
2. 数据压缩与优化
Hive集成压缩编解码器(如Snappy、GZIP),减少存储空间和I/O开销。结合ORC或Parquet格式,可进一步优化存储效率,降低云存储成本。
3. 元数据管理
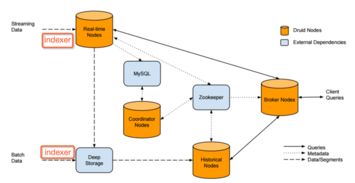
Hive使用元数据存储(如MySQL、PostgreSQL)管理表结构、分区信息和数据位置,确保数据一致性。元数据与HDFS等存储系统解耦,便于多用户协作和数据发现。
4. 集成与扩展性
Hive可与Hadoop生态系统无缝集成:
- 从HDFS、HBase或云存储(如S3)读取数据。
- 通过HiveServer2提供JDBC/ODBC接口,支持BI工具(如Tableau)直接连接。
- 结合Airflow等调度工具,构建自动化数据管道。
实际应用场景
- 数据仓库构建:企业常使用Hive整合多源数据(如日志、事务记录),构建中心化数据仓库,支持历史数据分析和报表生成。
- ETL处理:在数据湖中,Hive作为ETL引擎,清洗和转换原始数据,输出结构化数据集供下游应用使用。
- 即席查询:分析师通过HiveQL快速探索数据,无需编写复杂代码,加速业务洞察。
##
Hive通过类SQL接口和分布式计算框架,提供了强大的数据处理与存储支持服务。其分区、压缩和列式存储等优化机制,兼顾了性能与成本,使其成为大数据生态中不可或缺的组件。尽管实时处理能力有限,但在批处理和数据分析领域,Hive依然发挥着关键作用,助力企业挖掘数据价值。
如若转载,请注明出处:http://www.opulencespring.com/product/52.html
更新时间:2026-04-16 12:58:31