Dapper 分布式跟踪系统 数据处理与存储支持服务剖析
Dapper是谷歌开发的分布式跟踪系统,旨在解决大规模分布式环境下服务调用链路的监控与性能分析难题。其核心价值在于能够低开销、透明化地收集、处理和存储海量的跟踪数据,为系统性能诊断、故障定位和架构优化提供数据支撑。本文将深入解析Dapper在数据处理与存储层面的核心支持服务。
一、 数据处理流程:从采样到聚合
Dapper的数据处理并非记录每一次请求,而是通过采样机制来控制数据量。其核心处理流程包括:
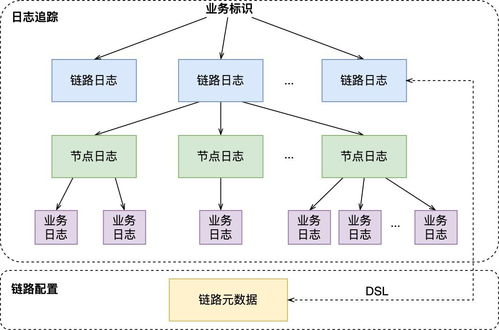
- 数据生成与收集:通过轻量级的代码植入(如线程局部存储),在服务调用的关键路径(如RPC)自动生成跟踪标识(TraceID、SpanID),并记录时间戳、注解等元数据,形成原始的“Span”数据。
- 异步写入与缓冲:生成的跟踪数据首先被写入本地日志文件或内存缓冲区。这种异步、批量写入的方式对应用性能影响极低(低侵入性)。
- 数据汇聚与中转:运行在每个机器上的Dapper守护进程定期收集本机的跟踪日志,并将其批量发送到中央的收集器(Collector) 集群。
- 清洗与标准化:收集器对接收到的原始Span数据进行校验、清洗,并将其转换为标准化的格式,为后续存储和索引做准备。
- 实时聚合与计算:部分关键指标(如错误率、延迟百分位数)会进行实时聚合计算,以支持监控仪表盘的快速展示。
二、 存储支持服务:多级索引与海量持久化
Dapper的存储设计需要应对每天数十亿甚至百亿级别的Span数据,其核心架构如下:
1. 核心存储:BigTable
Dapper选择谷歌的BigTable作为主存储。其设计充分利用了BigTable的特性:
- 表结构设计:主要使用两张表。
- Trace 表:以
TraceID作为行键,同一个Trace下的所有Span按时间顺序存储在同一行,便于高效重建完整调用链。
- 索引表:以
(服务名, 时间戳)等维度构建二级索引,支持按服务、时间范围等条件快速查找相关的TraceID。
- 数据生命周期:原始跟踪数据通常只保留有限时间(如几天),而聚合后的关键指标和采样后的“黄金信号”跟踪会被保留更长时间,以平衡存储成本与查询需求。
- 索引与查询服务
- Dapper构建了专用的索引服务,持续消费收集器输出的数据,为Trace数据建立多维索引(如服务、RPC方法、状态码、自定义注解等)。
- 面向用户的 Dapper API 和 Web UI 提供查询接口。用户可以通过服务名、时间范围、特定标签甚至延迟阈值来搜索跟踪记录。查询首先通过索引服务定位到TraceID,再从BigTable中读取详细的Span数据并组装成完整的调用链树进行可视化展示。
3. 数据聚合与归档
为了支持长期趋势分析和离线数据挖掘,Dapper会将数据定期归档到谷歌的Colossus文件系统中,并可能使用MapReduce或Dataflow等批处理框架进行离线分析,生成服务依赖图、性能基线报告等。
三、 核心设计思想与挑战应对
- 低开销与透明性:通过采样和异步缓冲写入,将性能影响控制在极低水平(如低于0.3%的延迟增加),使开发者无需修改业务代码即可享受跟踪能力。
- 可扩展性:收集器、存储(BigTable)和索引服务均采用分布式集群设计,可以水平扩展以应对数据量的增长。
- 时效性与一致性的权衡:跟踪数据追求近实时(分钟级)可用即可,这降低了对强一致性的要求,允许系统采用更高效、最终一致的分布式处理管道。
- 应对“大尾巴”延迟:通过针对性采样(如对慢请求进行更高概率采样),确保能够捕获到那些对系统性能影响最大的罕见长尾请求,为性能优化提供关键线索。
结论
Dapper的成功不仅在于其精巧的跟踪模型,更在于其背后强大、可扩展的数据处理与存储支持服务。它构建了一个从数据生成、收集、清洗、索引到存储查询的完整管道,并巧妙地平衡了性能开销、存储成本、查询效率与系统扩展性之间的关系。这一经典设计为后来众多的开源分布式跟踪系统(如Zipkin、Jaeger)提供了宝贵的蓝本,奠定了现代可观测性基础设施的重要基石。
如若转载,请注明出处:http://www.opulencespring.com/product/55.html
更新时间:2026-04-16 16:17:54